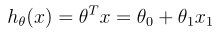In a previous article titled Easiest Machine Learning Algorithm Explained we introduced the Simple Linear Regression algorithm. Next we are going to talk about a specific tool and a particular problem we might solve with this approach.
Let’s say you are the CEO of a Software Corporation and you recently realized that Google paid $500 Million for a dozen deep-learning researchers in a single acquisition. Naturally, you might be considering to attract a few of this “unicorn” talents to develop a unique and rare potential acquisition value for your asset. To better describe these scenarios you would like to know how different number of experts in the staff managed to skyrocket the acquisition prices.
You might be tempted to use a traditional tools model to find out the numbers. But somehow the words that management author Ram Charan put in his latest book, “The Attacker’s Advantage” echoed from a corner of your mind:
“…any organization that is not a math house now or is unable to become one soon is already a legacy company”
To solve prediction problems in the present, corporations hire a lot of prediction experts and spend lots of resources. Fortunately, you can start with a lot simpler approach.
In this post I will give you the full procedure to develop this prediction model in what is called “simple linear regression” method. It’s a good starting point even for complex applications. You don’t even need expensive hardware. Everything has been tested on a regular desktop PC.
Data Gathering
You manage to put together the data relating the number of talents against the total acquisition price. You would like to use this data to help you verify how many talents will yield certain potential acquisition price for your corporation. You prepare a file that contains the dataset for our linear regression problem. The first column is the number of talents and the second column is the potential acquisition price.
For our theoretical example, in our case, we are using the number of talents to predict the potential acquisition price. In this case you would make the variable Y the potential acquisition price, and the variable X the number of talents. Hence Y can be predicted by X using the equation of a line if a strong enough linear relationship exists.
Implement Linear Regression in Octave
What is Octave?
Octave is a high-level interpreted programming language well-suited for numerical computations. It is an exellent language for matrix operations and can be good when working with a well defined feature matrix. It also has the most concise expression of matrix operations, so for many algorithms it is the one of choice. It provides capabilities for the numerical solution of linear and nonlinear problems. It also provides extensive graphics capabilities for data visualization and manipulation.
At the Octave command line, typing help followed by a function name displays documentation for a built-in function. For example, help plot will bring up help information for plotting. Further documentation for Octave functions can be found at the Octave documentation pages.
Version 4.0.0 has been released and is now available for download.
Understand the Data

Before starting on any task, it is often useful to understand the data by visualizing it. Once one or more variables have been saved to a file, they can be read into memory using the load command as follows:
data = load('acquisition.csv');
For this dataset, you can use a scatter plot to visualize the data, since it has only two properties to plot (number of talents and total acquisition price). The function plotData plots the data points x and y into a new figure:
The dataset is loaded from the data file into the variables X and y: The following snippet of code will prepare the function parameters and plot the data:
X = data(:, 1); y = data(:, 2); m = length(y); % number of training examples % Plot Data % Note: You have to complete the code in plotData.m plotData(X, y);
Computing the cost J(θ)
Lets define a cost function that measures how good a given prediction line is. This function will take in a pair and return an error value based on how well the line fits our data. We will iterate through each point in our data set and sum the square distances between each point’s y value and the candidate line’s y value to compute this error for a given line. It’s conventional to square this distance to make our function differentiable and to ensure that the result is always positive.

where the hypothesis h θ (x) is given by the linear model:

We are going to write a small function to compute cost for linear regression. Please note that multiplying a matrix of n row by a vector of n columns is equivalent to constructing polynomial expressions where the elements in the vector are the coefficient of the variables (which are evaluated to the values in the matrix). This is used to valuate the hypothesis parameters theta against the training values to get the current predictions. J = computeCost(X, y, theta) computes the cost of using theta as the parameter for linear regression to fit the data points in X and y. In Octave, computing the error for a given line will look like:
function J = computeCost(X, y, theta) m = length(y); % number of training examples J = 0; hTheta = X * theta; % Find the errors by substracting the predictions from the measured values (labels) errors = hTheta - y; squaredErrors = errors .^2; sumOfSquaredErrors = sum(squaredErrors); averageError = sumOfSquaredErrors / m; cost = averageError/2; J = cost; end
Implement Gradient Descent
 Lets walk through an example that demonstrates how gradient descent can be used to solve machine learning problems such as linear regression.
Lets walk through an example that demonstrates how gradient descent can be used to solve machine learning problems such as linear regression.
In this part, you will fit the linear regression parameters θ to our dataset using gradient descent. The parameter alpha is a learning rate usually just some small number that you can tune to adjust how fast your algorithm runs. Thus, gradient descent can be succinctly described in just a few steps:
-
Choose a random starting point for your variables.
-
Take the gradient of your cost function at your location.
-
Move your location in the opposite direction from where your gradient points, by taking your gradient ∇g, and subtract α∇g from your variables, where α is the learning rate.
-
Repeat steps 2 and 3 until you’re close to the minimum.
While debugging, it can be useful to print out the values of the cost function (computeCost) and gradient here. Function gradientDescent performs gradient descent to learn theta. It updates theta by taking num_iters gradient steps with learning rate alpha:
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters) m = length(y); % number of training examples J_history = zeros(num_iters, 1); for iter = 1:num_iters temp = theta; nFeaturesPlusOne = length(theta); for j = 1:nFeaturesPlusOne, predictions = (X * theta); delta = predictions - y; x = X(:,j); product = delta .* x; total = sum(product); temp(j) = theta(j) - (alpha * total) / m ; end; theta = temp; % Save the cost J in every iteration J_history(iter) = computeCost(X, y, theta); end end
Plot the Result

It is very usefull to visualize the outcome of the whole process. You can plot the training data and the regresion line into a figure using the “figure” and “plot” commands. Set the axes labels using the “xlabel” and “ylabel” commands. Assume the data have been passed in as the x and y arguments of this function.
The command that actually generates the plot is, of course, plot(x, y). Before executing this command, we need to set up the variables, x and y. The plot function simply takes two vectors of equal length as input, interprets the values in the first as x-coordinates and the second as y-coordinates and draws a line connecting these coordinates.
You can use the ‘rx’ option with plot to have the markers appear as red crosses. Furthermore, you can make the markers larger by using plot(…, ‘rx’, ‘MarkerSize’, 10);
figure; % open a new figure window
plot(x, y, 'rx', 'MarkerSize', 10); % Plot the data
ylabel('Value in $1,000,000s');
xlabel('Unicorns '); % Set the x?axis label
Visualizing the Cost Function
 We can plot a grid of the parameter space for the cost function. Octave surf defines a surface by the z-coordinates of points above a grid in the x–y plane, using straight lines to connect adjacent points. The
We can plot a grid of the parameter space for the cost function. Octave surf defines a surface by the z-coordinates of points above a grid in the x–y plane, using straight lines to connect adjacent points. The mesh and surffunctions display surfaces in three dimensions. Mesh produces wireframe surfaces that color only the lines connecting the defining points. Surf displays both the connecting lines and the faces of the surface in color. Octave colors surfaces by mapping z-data values to indexes into the figure colormap.

% Grid over which we will calculate J theta0_vals = linspace(-30, -10, 100); theta1_vals = linspace(30, 50, 100); % initialize J_vals to a matrix of 0's J_vals = zeros(length(theta0_vals), length(theta1_vals)); % Fill out J_vals for i = 1:length(theta0_vals) for j = 1:length(theta1_vals) t = [theta0_vals(i); theta1_vals(j)]; J_vals(i,j) = computeCost(X, y, t); end end
Because of the way meshgrids work in the surf command, we need to transpose J_vals before calling surf, or else the axes will be flipped:
J_vals = J_vals';
figure;
surf(theta0_vals, theta1_vals, J_vals)
xlabel('\theta_0'); ylabel('\theta_1');
From this second plot, you can see we did pretty well in finding the minimum of the cost function.
Predict Corporate Value
predict1 = [1, 3] *theta;fprintf('For a prospect holding 3 Deep Learning experts in staff, we predict a corporate value of %f\n',...predict1*1000000);predict2 = [1, 7] * theta;fprintf('For a prospect holding 7 Deep Learning experts in staff, we predict a corporate value of %f\n',...predict2*1000000); |
These are the results:
Running Gradient Descent ...ans = 1.7826e+004Theta found by gradient descent: -20.558551 40.750470For a prospect holding 3 Deep Learning experts in staff, we predict a corporate value of 101692858.248413For a prospect holding 7 Deep Learning experts in staff, we predict a corporate value of 264694736.916260 |
Exercise Your Visualization Skills
Visualizing and communicating data at new companies who are making the first steps in data-driven decisions is extremely important. It is important to be familiar with the principles behind visually encoding data and communicating information as well as with the tools necessary to visualize data. You need to describe your findings or the way that work to both technical and non-technical audiences.
To put the cherry on the cake and exercise your visualization skills you can create a nice infographic that would add a bit of drama to your findings

 The goal of simple linear regression is to fit a line to a set of points. In other words, we attempt to describe the relationship between one variable from the values on a second variable. The straight line used asa linear relationship to predict the numerical value of Y for a given value of X using is called the regression line.
The goal of simple linear regression is to fit a line to a set of points. In other words, we attempt to describe the relationship between one variable from the values on a second variable. The straight line used asa linear relationship to predict the numerical value of Y for a given value of X using is called the regression line.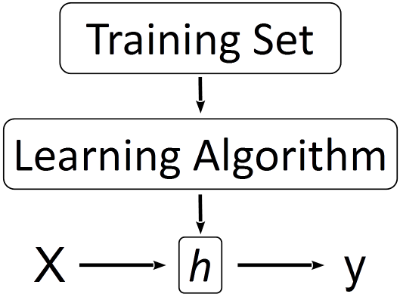 The hypothesis here is nothing but a linear equation which resembles the equation of a line. Our hypothesis function has the general form: hθ(x)=θ0+θ1x where θ1 is the slope of the line and θ0 is the constant.
The hypothesis here is nothing but a linear equation which resembles the equation of a line. Our hypothesis function has the general form: hθ(x)=θ0+θ1x where θ1 is the slope of the line and θ0 is the constant.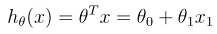
 The black diagonal line in the figure is the regression line and consists of the predicted score on Y for each possible value of X. The vertical lines from the points to the regression line represent the errors of prediction. As you can see, the red point is very near the regression line; its error of prediction is small. By contrast, the yellow point is much higher than the regression line and therefore its error of prediction is large.
The black diagonal line in the figure is the regression line and consists of the predicted score on Y for each possible value of X. The vertical lines from the points to the regression line represent the errors of prediction. As you can see, the red point is very near the regression line; its error of prediction is small. By contrast, the yellow point is much higher than the regression line and therefore its error of prediction is large. The gradient of a function is a vector which points towards the direction of maximum increase. Consequently, in order to minimize a function, we just need to take the gradient, look where it’s pointing, and head the other direction.
The gradient of a function is a vector which points towards the direction of maximum increase. Consequently, in order to minimize a function, we just need to take the gradient, look where it’s pointing, and head the other direction.